life is too short for a diary
Pandas inner join on dataframes


Performing inner join on pandas dataframe is straightforward. However I wanted to override values from the right dataframe.
Let us assume we have two dataframes as
import pandas as pd
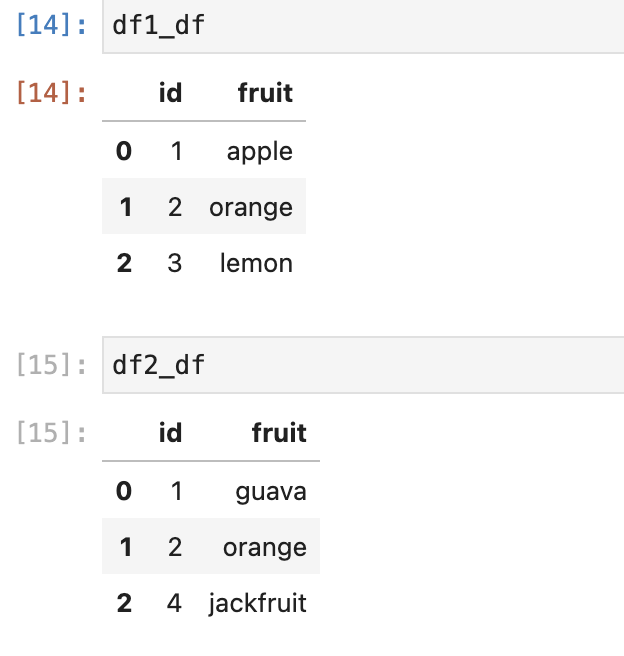
df1_data = [[1, 'apple'], [2, 'orange'], ['3', 'lemon']]
df1_df = pd.DataFrame(df1_data, columns = ['id', 'fruit'])
df2_data = [[1, 'guava'], [2, 'orange'], ['4', 'jackfruit']]
df2_df = pd.DataFrame(df2_data, columns = ['id', 'fruit'])
We can visualize these dataframes as
 |
Cast column id as integer
df1_df['id'] = df1_df['id'].astype(int)
df2_df['id'] = df2_df['id'].astype(int)
We can perform a simple inner join on key id
df1_df.merge(df2_df, on='id', how='inner')
 |
Since we need to retain right column , so we can rename columns from the left with suffix as dup
df = df1_df.merge(df2_df, on='id', how='inner', suffixes =('_dup', ''))
 |
We can drop rows where fruit_dup is not equal to fruit column since we are only interested in differences.
df = df[df['fruit_dup'] != df['fruit']]
 |
Lastly we can drop the _dup column
del df['fruit_dup']
comments powered by Disqus